


【摘 要】随着经济社会的发展,互联网已成为人们获取医疗保健信息、医疗服务的主要途径之一。然而互联网信息数量庞大,传统的搜索引擎难以提供准确的医疗建议信息。本文基于知识图谱构建了一种医疗信息问答系统,由数据层、处理层、对话服务层等三个部分组成。系统以医疗领域知识图谱为支撑,通过命名实体识别模型和意图识别模型解析用户的自然语言输入,采用Cypher 查询语句检索医疗信息知识并反馈结果,通过交互界面将结果反馈给用户,从而提供医疗信息知识的问答服务。经实验测试,本系统能准确提取和识别问句中的有效信息并提供精准反馈回答,实现了医疗信息的智能问答,为公众提供了一种有效的医疗健康知识查询工具。
【关键词】对话机器人;知识图谱;智能问答
引言
国家卫生健康委员会发布的《健康中国行动(2019—2030 年)》提出,鼓励研发推广健康管理类人工智能,运用健康大数据提高大众自我健康管理能力。截至2024 年6 月,我国网民规模达10.99 亿,互联网医疗用户已达3.63 亿,线上问诊功能使用人群占比达59.1%。然而,传统搜索引擎返回的医疗信息往往需要用户自行筛选,且错误信息可能误导用户。近年来,基于知识图谱的智能对话系统在医疗领域得到广泛应用,能够通过实体识别和意图识别算法,快速准确地提供医疗健康信息,满足用户需求。相比传统对话系统,知识图谱在复杂语言环境中表现更优,能够有效提升医疗信息服务的精准性和效率。
一、系统总体设计
本系统以大众在医疗保健领域的需求为出发点,通过知识图谱的数据支撑,以对话框文字交流为交互形式,为用户提供科学的医疗保健服务。医疗信息智能对话机器人系统总体架构分为数据层、处理层、对话服务层3 个部分,如图1 所示。
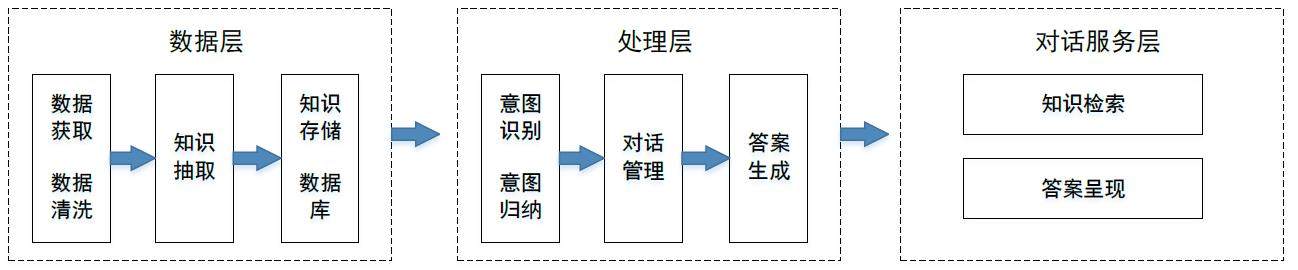
数据层是医疗信息智能对话机器人系统的底层数据支撑。本系统根据用户的需求,从专业网站获取相关数据,对数据进行清洗和处理后,抽取出实体、属性和关系等信息,存入知识数据库中[1]。
处理层通过意图理解和实体抽取算法识别用户的意图和问题中的实体,根据用户的需求进行数据查询,在知识图谱中推理出结果。在语言生成模块中,将推理结果填入模板中反馈给对话服务层[2]。
对话服务层是用户操作及信息展示的界面。系统采用Flask部署和维护理解模型,响应用户的输入请求及推送消息,完成前后端的数据交互与通信[3]。
二、数据获取
医疗信息智能对话机器人系统以大量的医疗数据为基础。数据类型分为结构化数据、半结构化数据和非结构化数据。结构化数据具有严格格式和长度规范,由二维表存储表达并实现逻辑结构,通过关系型数据库进行存储和管理。半结构化数据的数据库是节点的集合,每个节点至少有一条外向的弧,每条弧都有一个标签,该标签指明弧开始处的节点与弧末端节点之间的关系。由于半结构化数据没有固定的结构,因此需对其进行数据预处理转换为结构化数据。本项目的数据来源于99 健康网,通过python 爬虫脚本获取9000个页面,将数据存储为json 格式[4]。
三、数据处理
从网页上获取的医疗数据存在信息重复、格式混乱、无效等问题,因此需对这些数据进行清洗去除换行符等冗余信息。使用json 模块中的dumps、dump、loads、load 四个方法对数据文件进行读取与存储。json.dumps() 用于将dict类型的数据转成str,json.loads() 用于将str 类型的数据转成dict,json.dump() 用于将dict 类型的数据转成str 并写入到json 文件中,json.load() 用于从json 文件中读取数据。通过正则表达式处理数据字符串,识别指定分隔符号切分字符串。

