


【摘 要】本研究基于飞桨深度学习框架,探讨了电影推荐系统的设计与实现。推荐系统在信息时代中扮演着关键角色,能满足用户个性化需求、提高信息获取效率。本研究针对推荐系统的挑战,提出了一种基于深度学习的电影推荐模型;通过收集和分析用户历史行为数据,构建了用户——电影交互矩阵,并利用飞桨深度学习框架建立了多层神经网络模型,结合用户和电影特征进行训练和优化。实验证明,该模型在准确性和效率方面显著增强,提升了推荐系统的用户体验和满意度。
【关键词】飞桨;电影推荐;用户——电影交互;深度学习框架
引言
随着科技和信息技术的发展,“信息过载”使得用户很难在大量电影资源中快速、准确地获取自己想要的内容,成为影响用户体验的主要制约因素[1]。因此,个性化的电影推荐成为新时代研究的重点。本文聚焦于一个基于飞桨(PaddlePaddle)深度学习平台的创新电影推荐系统,飞桨不仅是中国首个自主研发的开源深度学习平台,集深度学习训练和预测框架、模型库、工具组件等功能于一身[2];同时也是国内唯一功能完备的端到端开源深度学习平台,拥有五大优势:兼顾灵活性和高性能的开发机制、工业级应用效果的模型、超大规模并行深度学习能力、推理引擎一体化设计以及系统化服务支持[3]。研究旨在利用飞桨平台的核心优势和深度学习技术,分析用户数据,构建精准的推荐算法,并实现一个高效的推荐模型,以提供个性化的电影推荐;通过对系统的全面剖析,旨在提供一个智能推荐系统开发的完整视角,并展现飞桨平台在支持这一过程中的关键作用[4]。
一、数据来源与预处理
本研究采用了飞桨平台所提供的ml-1m 电影推荐数据集, 该数据集源自GroupLens Research 组织下的MovieLens 网站,是一个内容丰富、包含大量电影评分信息的数据集[5],它涵盖了用户对大约3900 部电影的100 万条评分记录。数据集被细致地划分为用户属性、电影属性和评分信息的文本文件。以下是用于加载和解析数据的核心代码,其中只展示了处理用户信息的部分:
usr_info, max_usr_id, max_usr_age, max_usr_job=get_usr_info(usr_file)
数据预处理阶段,首先读取并解析了用户、电影和评分的相关数据;接下来将这些信息储存于结构化的字典中;最后将整个数据集分割为训练集和验证集(比例为8.5∶1.5),并创建了一个批次数据迭代器,为接下来的模型训练做好了准备。以下是用于数据划分和创建数据迭代器的核心代码。
Tset=dataset[:int(0.85*len(dataset))]
Vset=dataset[int(0.85*len(dataset)):]
train_loader=DataLoader(MovieDataset(Tset, use_poster), batch_size=BATCH_SIZE, shuffle=True)
valid_loader=DataLoader(MovieDataset(Vset, use_poster), batch_size=BATCH_SIZE, shuffle=False)
二、模型构建
模型的核心构建块是嵌入层,它负责将用户的离散特征,如ID、性别、年龄和职业,转化为连续的向量形式。这些向量经过全连接层和ReLU 激活函数进一步处理,以提取更深层次的特征信息。鉴于数据不能直接被神经网络处理,不适宜直接作为神经网络的输入,因此采用了词嵌入技术,将这些离散的数值映射成固定长度的向量。
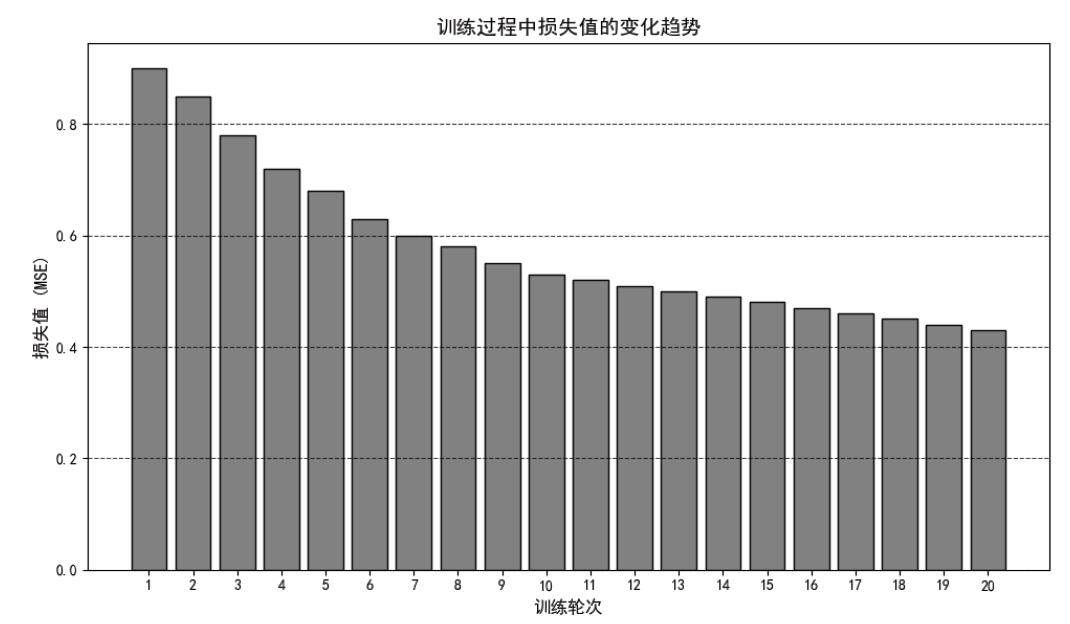
该模型旨在捕捉用户和电影的细微差别,通过计算用户和电影特征的相似度来推荐电影:首先,从用户和电影中提取特征并转换为向量;然后,通过全连接层或卷积层进一步处理这些向量;接着,将这些向量融合成一个单一的表示,以便于计算相似度;最后,使用余弦相似度作为优化的损失函数,衡量用户特征与电影特征之间的相关性。

