



摘 要:作為一种结构化的语义知识库,知识图谱近年来被多个领域所应用,然而在机器学习这一专有领域仍存在空缺。文章描述了如何构建一个面向机器学习领域的知识图谱,并基于该图谱设计了一个问答系统。在图谱的构建过程中,主要使用了爬虫技术以及部分 NL.P 方法对数据进行采集和处理,最终得到1个包含2442 个实体的知识图谱,并将其存储在 Neo4i 图数据库中。针对间答系统设计部分结合基于规则正则匹配以及基于词向量相似度匹配的方法,构建了问答模块。该领域图谱的构建和问答系统的设计,将使研究人员和爱好者更轻松地获取高质量的机器学习领域的知识。
关键词:知识图谱:问答系统;机器学习
中图法分类号:TP18文献标识码:A
1 引言
知识图谱的起源可追溯到20 世纪30 年代,但其正式概念是由Google 于2012 年提出的。它被描述为一个提供智能搜索服务的大型知识库,可以将独立的知识以三元组的形式形成语义知识的一种形式化描述框架,形式化地描述真实世界中各类事物及其关联关系[1] 。领域知识图谱是特定领域应用的知识图谱,在金融、军事、医疗等多个领域都得到了应用,如IBMWatson Health 医疗知识图谱[2] 。由于知识图谱的结构化程度高且知识质量高,基于知识图谱的问答系统越来越受到人们的青睐,它弥补了传统问答系统检索效率低和检索知识质量不高的缺点。
如今,机器学习的热度不断上升,然而当前机器学习领域图谱的开发仍处于空白阶段。为了使机器学习专有领域的知识能够形成一个结构化的语义网络,以及为机器学习领域的相关研究提供便利,本文将介绍机器学习领域图谱的构建过程,并基于图谱设计一个问答系统。
2 基本技术概述
2.1 知识图谱构建理论
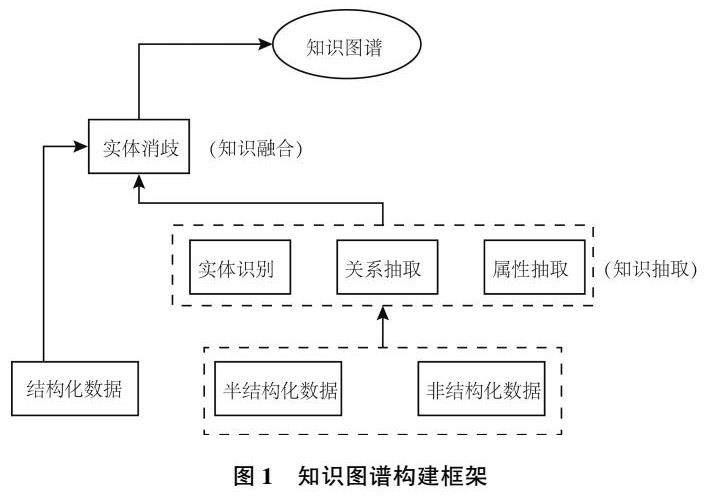
知识图谱的构建通常包含知识抽取、知识融合、知识加工和知识更新等步骤[3] 。获取相关语料后,需要对语料进行预处理,然后进入知识抽取环节。知识抽取主要包括实体识别、关系抽取以及属性抽取3 类任务。实体识别用于识别文本中的特殊实体,关系抽取用于从文本中识别实体之间的关系,属性抽取用于从文本中提取实体的属性。
这些任务的完成早期依赖于专家手工定义规则,而基于机器学习方法的技术现在更为实用。本文主要使用基于机器学习的方法进行知识抽取,同时使用了OCR 技术以及爬虫技术。在知识融合阶段,主要工作有实体对齐、实体消歧,本文通过基于机器学习的方法来完成这些任务。完成上述工作后,需要将知识图谱数据存储到数据库中。根据存储方式的不同,知识图谱通常可以存储在RDF 数据库、关系型数据库或者图数据库中。本文使用Neo4j 图数据库对知识图谱进行存储[4] 。
2.2 基于知识图谱的问答系统设计理论
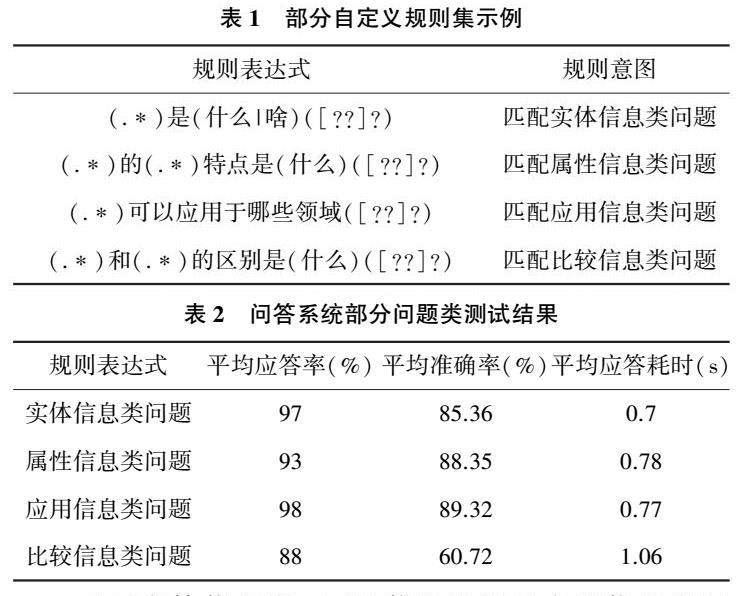
构建基于知识图谱的问答系统通常有3 种方法:基于模板匹配;基于语义解析;基于向量建模[5] 。本文将结合基于规则正则匹配的方法和基于Word2Vec向量建模的方法,提升智能问答的应答率、准确率。
3 机器学习领域图谱构建
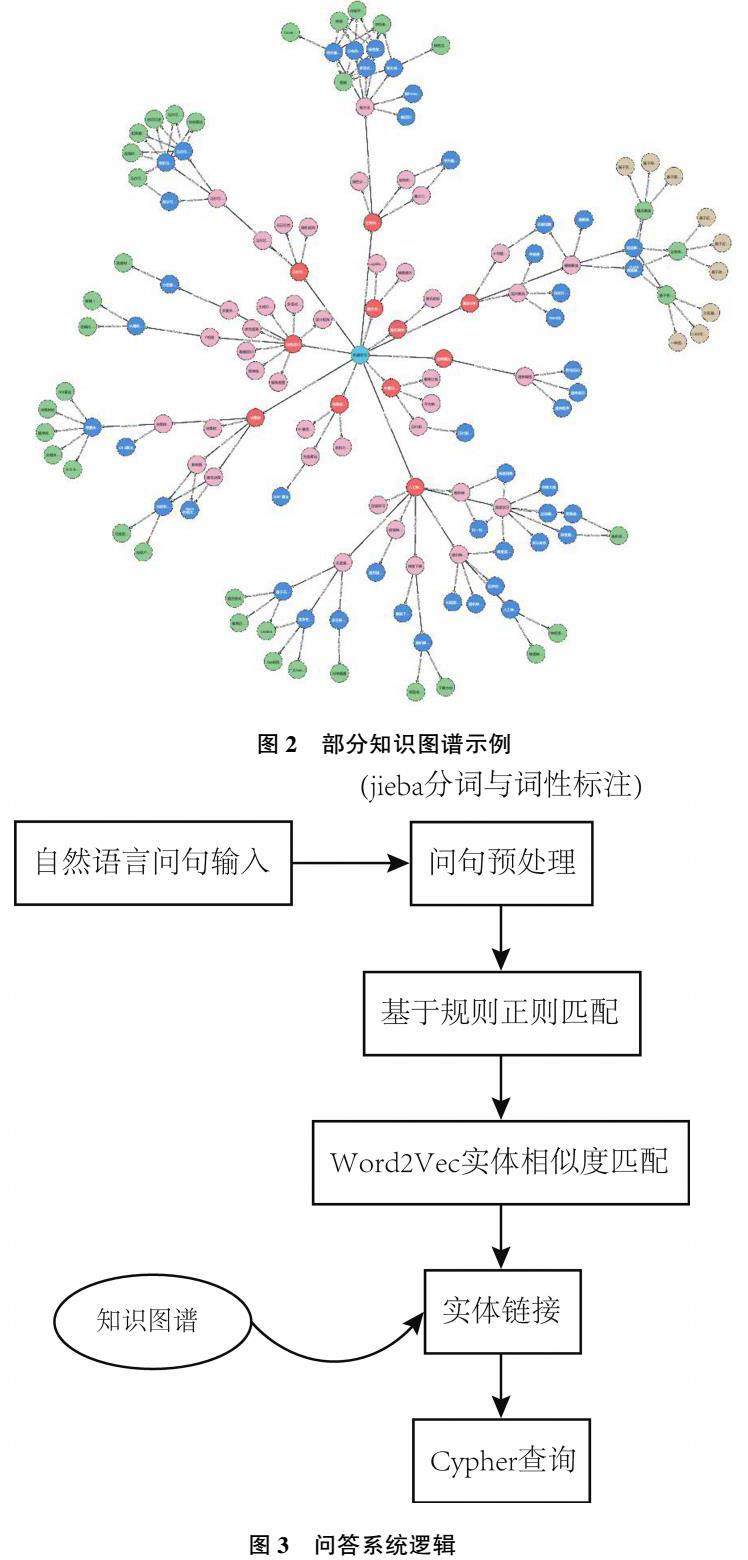
本文采用自底向上的框架构建机器学习领域的知识图谱,基本流程如图1 所示。
3.1 数据采集
构建知识图谱首先需要收集相关语料。为了保证实体词的专业性,本文参考了机器之心团队编写的专有术语库,其中收纳了2 442 个机器学习专有领域的术语,这些术语来源于领域专家以及权威教科书等,并经过了校对等工作,具有较强的专业性与公信力。本文以这些术语为基础,建立关键词表,并将其作为图谱的实体词库。
以实体词库中的专业词汇为关键词,利用网络爬虫技术从万方、维普数据库中获取了23 579 篇包含这些关键词的期刊文献,并使用request 库、BS4 库等工具对每个实体词的百度百科词条以及维基百科词条进行爬取,在后续知识抽取的步骤中会对这些数据进行进一步处理。


